Memory operation ordering is a complicated set of rules with issues that are not specific to SGI Altix systems but rather to any Linux platforms with Intel Itanium 2-based processors. Similarly, this topic is not related to PIO posted operations.
The compiler can reorder instructions and also optimize away instructions that appear to be superflous or are not used. One technique it might use is to preload some registers, whose contents might or might not be valid by the time they are needed and used.
One optimization feature of Intel Itanium 2 processors is that they can reorder instructions such that some instructions are scheduled and completed not exactly in the order that they appear in your program. For more information regarding memory ordering, memory fences, and so on, see the Intel Itanium 2 Processor Reference Manual for Software Development and Optimization and Intel Itanium Architecture Software Developer's Manual on for additional information on MP coherence and synchronization.
This appendix describes the following memory operation aspects of SGI Altix systems:
Memory ordering
Release semantics
Acquire semantics
Memory fencing
Memory load and store operations on SGI Altix platforms will not necessarily complete (that is, be visible in memory to other CPUs) in program order. For example, consider the following code snippet (program order):
1: ld r1=[r2] // r1 = *r2 2: st [r4]=r6 // *r4 = r6 3: ld r8=[r9] // r8 = *r9 4: st [r22]=r3 // *r22 = r3 |
This code could actually execute in the following order:
Register r1 is set to the value at memory address r2.
Register r8 is set to the value at memory address r9.
The address in r22 is set to the value in r3.
The address in r4 is set to the value in r6.
| Note: This is a separate issue from compiler reordering, as it occurs at runtime. This also assumes that the pointers in question point to non-overlapping addresses. The kind of reordering shown in the previous example can expose bugs of various types, some of them very similar to the PIO ordering and coherency issues explained in this document. |
Using release semantics on an Intel Itanium 2 processor, the programmer can ensure that all previous memory accesses are made visible prior to the st.rel process, though subsequent memory accesses may “float up” above st.rel. For example, consider the following code sample:
1: st [r1]=r2 // cannot move below 2 2: st.rel [r4]=r6 // will be visible only after 1 is visible 3: ld r8=[r9] // may be reordered 4: st [r22]=r3 // may be reordered |
The processor will guarantee that the memory reference on line 1 is visible before the the st.rel on line 2; that is, the following sequence could be the actual execution order:
The address in r1 is set to the value in r2.
The address in r22 is set to the value in r3.
The address in r4 is set to the value in r6 (will happen after one register r8 is set to the value at memory address r9).
In other words, no prior memory references (in program order) are allowed to propagate below a store with release semantics, but memory references following an st.rel might “float up” above the st.rel instruction.
Release semantics is a one-directional fence that prevents “Downward” drift as shown in Figure 2-1.
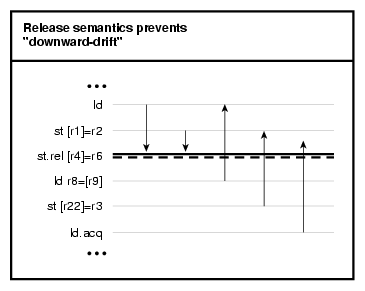
For more information on release semantics, see the Intel Itanium 2 Processor Reference Manual for Software Development and Optimization and Intel Itanium Architecture Software Developer's Manual.
Using so-called “acquire” semantics, the programmer can ensure that a load is made visible before all subsequent data accesses, though previous memory accesses can propagate below an ld.acq process. For example, consider the following code sample:
1: ld r44=[r23] // *can* move below 2 2: ld.acq r1=[r2] // will be visible before 3 3: ld r8=[r9] // cannot move above 2 4: st [r4]=r6 // cannot move above 2 5: st [r22]=r3 // cannot move above 2 |
The processor will ensure that the memory accesses prior to line 3 (in program order) are made visible before any subsequent accesses. So the following sequence could be executed by the processor:
Register r1 is set to the value at memory address r2 (will happen before 2).
Register r8 is set to the value at memory address r9.
The address in r4 is set to the value in r6.
Register r44 is set to the value at memory address r23.
The address in r22 is set to the value in r3.
Acquire semantics is a one-directional fence that prevents “Upward” drift as shown in Figure 2-2.
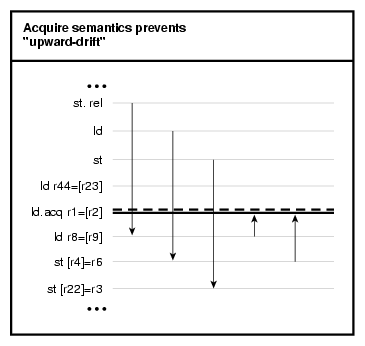
.
For more information on acquire semantics, see the Intel Itanium 2 Processor Reference Manual for Software Development and Optimization and Intel Itanium Architecture Software Developer's Manual.
A memory fence acts as a simple, two-way barrier for memory operations as shown in Figure 2-3. For example, consider the following snippet:
1: ld r1=[r2] <--\ 2: st [r4]=r6 <--- neither can move below 3 3: mf 4: ld.acq r8=[r9] <-- neither can move above 3 5: st [r22]=r3 <----/ |
Lines 1 and 2 are guaranteed to be visible before any subsequent memory accesses (like those on lines 4 and 5), and memory accesses following the fence will not be visible to instructions before the memory fence (in program order).
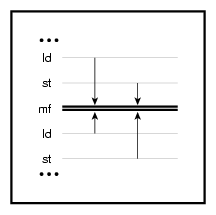
For more information on memory fencing semantics, see the Intel Itanium 2 Processor Reference Manual for Software Development and Optimization and Intel Itanium Architecture Software Developer's Manual.