This chapter provides information on configuring your system and covers the following topics:
CPU frequency scaling is disabled by default on your SGI Altix UV 100 or Altix UV 1000 series system. This is accomplished by adding the acpi-cpufreg file to the /etc/modprobe.d directory.
An example is, as follows:
admin:/etc/modprobe.d # cat acpi-cpufreq # comment out the following line to enable CPU frequency scaling install acpi-cpufreq /bin/true |
To enable CPU frequency scaling, log into your Altix UV system (ssh root@hostname) and remove the acpi-cpufreg file in the /etc/modprobe.d directory. If your system is partitioned, you need to perform this on each partition.
If you decide to enable CPU frequency scaling on your system, SGI highly recommends that you set the default scaling governor to performance using the following script:
maxcpu=`grep processor /proc/cpuinfo | awk '{print $3}' | tail -1`
for cpu in `seq 0 $maxcpu`
do
cpufreq-set -c $cpu -g performance
done
|
| Note: In order to enable the Intel processor's Turbo boost feature, CPU frequency scaling has to be enabled. |
This section describes how to partition an SGI ProPack server and contains the following topics:
A single SGI ProPack for Linux server can be divided into multiple distinct systems, each with its own console, root filesystem, and IP network address. Each of these software-defined group of processor cores are distinct systems referred to as a partition. Each partition can be rebooted, loaded with software, powered down, and upgraded independently. The partitions communicate with each other over an SGI NUMAlink connection called cross-partition communication . XPNET is the TCP/IP interface for cross-partition communication over NUMAlink. Collectively, all of these partitions compose a single, shared-memory cluster.
Direct memory access between partitions, sometimes referred to as global shared memory, is made available by the XPC and XPMEM kernel modules. This allows processes in one partition to access physical memory located on another partition. The benefits of global shared memory are currently available via SGI's Message Passing Toolkit (MPT) software. For more information on MPT, see the Message Passing Toolkit (MPT) User's Guide.
Partition discovery software allows all of the partitions to know about each other.
Partition firewalls provide memory protection for each partition. XPMEM software uses firewall code to open up a portion of memory so that is can be accessed by CPU cores in other partitions. Firewalls have kernel, BIOS, and hardware components. The kernel component is XPMEM. XPMEM allocates some memory and makes a BIOS call passing BIOS the memory address. The BIOS calls allow the UV hub hardware to change the memory protections on each of the cache lines in the block of memory. Hardware memory directory bits indicate which nodes have access to that cache line. Nodes in the partition always have access to memory in their own partition. Nodes outside the partition do not have access, unless the memory is opened up by XPMEM.
A coherence domain is the extent to which a CPU core is able to coherently load and store cacheable memory. Usually, a coherence domain is the same as an operating system partition or single-system image. With XPMEM, the coherence domain can be expanded to include memory in other partitions. Expanding the coherence domain is part of the process of opening up the memory in a remote partition.
A heartbeat mechanism allows each partition to determine the state of all partitions in the system. Each partition increments its own heartbeat which is read by other partitions. As long as the local partition keeps incrementing its heartbeat, the other partitions know that it is still operational.
Each partition has a partition page that stores its heartbeat. A partition page is a page of physical memory that contains information about the local partition and whose address is known by the other partitions in the system.
Reset fences are special hardware mechanisms built into the NUMAlink ports of hubs and routers that prevent resets from propagating into a partition. Reset fences are set at the partition boundaries. BIOS sets up the reset fences after it does NUMAlink discovery.
The global reference unit (GRU) no-fault code allows a partition to accesses a remote partition safely. If the remote access fails, the GRU no-fault code cleans up the GRU so it can be reused.
All of the partitions in a partitioned system have the same system serial number. The system serial number is stored in the system controller.
It is relatively easy to configure a large SGI Altix system into partitions and reconfigure the machine for specific needs. No cable changes are needed to partition or repartition an SGI Altix machine. Partitioning is accomplished by commands sent to the system controller. For details on system controller commands, see the SGI UV System Software Controller User's Guide.
This section describes the advantages of partitioning an SGI ProPack server as follows:
You can use SGI's NUMAlink technology and the XPC and XPMEM kernel modules to create a very low latency, very large, shared-memory cluster for optimized use of Message Passing Interface (MPI) software and logically shared, distributed memory access (SHMEM) routines. The globally addressable, cache coherent, shared memory is exploited by MPI and SHMEM to deliver high performance.
Another reason for partitioning a system is fault containment. In most cases, a single partition can be brought down (because of a hardware or software failure, or as part of a controlled shutdown) without affecting the rest of the system. Hardware memory protections prevent any unintentional accesses to physical memory on a different partition from reaching and corrupting that physical memory. For current fault containment caveats, see “Limitations of Partitioning”.
Partitions can be of different sizes, and a particular system can be configured in more than one way. For example, a 128-processor system could be configured into four partitions of 32 CPU cores each or configured into two partitions of 64 CPU cores each. (See "Supported Configurations" for a list of supported configurations for system partitioning.)
Your choice of partition size and number of partitions affects both fault containment and scalability. For example, you may want to dedicate all 64 CPU cores of a system to a single large application during the night, but then partition the system in two 32 processor systems for separate and isolated use during the day.
One of the fundamental factors that determines the performance of a high-end computer is the bandwidth and latency of the memory. The SGI NUMAflex technology gives an SGI ProPack partitioned, shared-memory cluster a huge performance advantage over a cluster of commodity Linux machines (white boxes). If a cluster of N white boxes, each with M CPUs is connected via Ethernet or Myrinet or InfinaBand, an SGI ProPack system with N partitions of M CPUs provides superior performance because of the significantly lower latency of the NUMAlink interconnect, which is exploited by the XPNET kernel module.
Partitioning can increase the reliability of a system because power failures and other hardware errors can be contained within a particular partition. There are still cases where the whole shared memory cluster is affected; for example, during upgrades of harware which is shared by multiple partitions.
If a partition is sharing its memory with other partitions, the loss of that partition may take down all other partitions that were accessing its memory. This is currently possible when an MPI or SHMEM job is running across partitions using the XPMEM kernel module.
Failures can usually be contained within a partition even when memory is being shared with other partitions. XPC is invoked using normal shutdown commands such as reboot(8) and halt(8) to ensure that all memory shared between partitions is revoked before the partition resets. This is also done if you remove the XPC kernel modules using the rmmod (8) command. Unexpected failures such as kernel panics or hardware failures almost always force the affected partition into the KDB kernel debugger or the LKCD crash dump utility. These tools also invoke XPC to revoke all memory shared between partitions before the partition resets. XPC cannot be invoked for unexpected failures such as power failures and spontaneous resets (not generated by the operating system), and thus all partitions sharing memory with the partition may also reset.
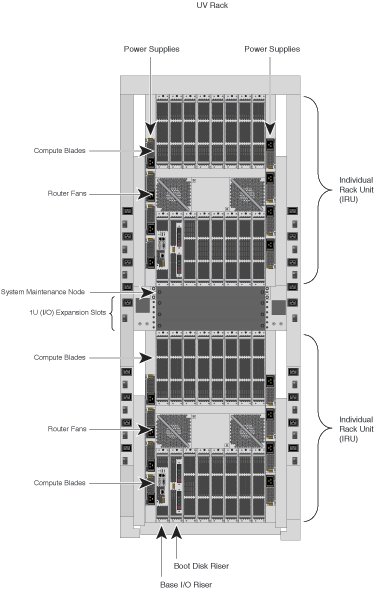
See the SGI UV 1000 System User's Guide for information on configurations that are supported for system partitioning. The SGI Altix UV 1000 system sizes range from 2 to 128 blades (16 to 2048 cores) in a single system image (SSI). See Figure 2-1.
The maximum number of processor cores in an SSI is 2048. The following describe the minimum and maximum metrics within an SSI:
one partition
one to four racks
one to eight individual rack units (IRUs) with maximum of two IRUs per rack
one to eight Base I/O (only one Base I/O has the capability to boot the system)
two to 128 compute blades
two to 128 Altix UV Hubs (one Hub on each compute blade)
two to 256 processor sockets (one socket on memory expansion blade, two sockets on compute blade)
16 to 2048 processor cores (up to 4096 threads with Hyper-Threading enabled)
eight to 2048 DDR3 memory DIMMs (16 DIMMs maximum per compute blade)
Up to 16 terabytes (TBs) with up to 4 TB per rack (using 8 GB DIMMs)
Currently, the Linux operating system only supports 2048 cores/threads.
| Note: The terms single system image (SSI) and partition can be used interchangeably. |
For additional information about configurations that are supported for system partitioning, see your sales representative.
To enable or disable partitioning software, see “Partitioning Software”, to use the system partitioning capabilities, see “Partitioning a System” and “Partitioning a System”.
This section covers the following topics:
SGI ProPack for Linux servers have XP, XPC, XPNET, and XPMEM kernel modules installed by default to provide partitioning support. XPC and XPNET are configured off by default in the /etc/sysconfig/sgi-xpc and /etc/sysconfig/sgi-xpnet files, respectively. XPMEM is configured on by default in the /etc/sysconfig/sgi-xpmem file. To enable or disable any of these features, edit the appropriate /etc/sysconfig/ file and execute the /etc/init.d/sgi-xp script.
On SGI ProPack systems running SLES11, if you intend to use the cross-partition functionality of XPMEM, you will need to add xpc to the line in the /etc/sysconfig/kernel file that begins with MODULES_LOADED_ON_BOOT. Once that is added, you may either reboot the system or issue an modprobe xpc command to get the cross-partition functionality to start working. For more information on using modprobe, see the modprobe(8) man page.
The XP kernel module is a simple module which coordinates activities between XPC, XPMEM, and XPNET. All of the other cross-partition kernel modules require XP to function.
The XPC kernel module provides fault-tolerant, cross-partition communication channels over NUMAlink for use by the XPNET and XPMEM kernel modules.
The XPNET kernel module implements an Internet protocol (IP) interface on top of XPC to provide high-speed network access via NUMAlink. XPNET can be used by applications to communicate between partitions via NUMAlink, to mount file systems across partitions, and so on. The XPNET driver is configured using the ifconfig commands. For more information, see the ifconfig(1M) man page. The procedure for configuring the XPNET kernel module as a network driver is essentially the same as the procedure used to configure the Ethernet driver. You can configure the XPNET driver at boot time like the Ethernet interfaces by using the configuration files in /etc/sysconfig/network-scripts. To configure the XPNET driver as a network driver see the following procedure.
The procedure for configuring the XPNET driver as a network driver is essentially the same as the procedure used to configure the Ethernet driver (eth0), as follows:
Log in as root.
For SGI ProPack systems, configure the xp0 IP address using yast2. For information on using yast2, see SUSE Linux Enterprise Server 11 Administration Guide . The driver's full name inside yast2 is SGI Cross Partition Network adapter.
Add the network address for the xp0 interface by editing the /etc/hosts file.
Reboot your system or restart networking.
The XPMEM kernel module provides direct access to memory located on other partitions. It uses XPC internally to communicate with XPMEM kernel modules on other partitions to accomplish this. XPMEM is currently used by SGI's Message Passing Toolkit (MPT) software (MPI and SHMEM).
This section describes how to partition your system. The following example shows how to use chassis manager controller (CMC) software to partition a two rack system containing four IRUs into four distinct systems, use the uvcon command to open a console and boot each partition and repartiton it back to a single system.
| Note: Each partition must have one base I/O blade and one disk blade for booting. 001i01b00 refers to rack 1, IRU 0, and blade00. r001i01b01 refers to rack 1, IRU 0, and blade01. |
Base I/O and the boot disk are displayed by the config -v command, similar to the following:
r001i01b00 IP93-BASEIO r001i01b01 IP93-DISK |
To partition your system, perform the following steps :
Use the hwcfg command to create four system partitions, as follows:
CMC:r1i1c>hwcfg partition=1 "r1i1b*" CMC:r1i1c>hwcfg partition=2 "r1i2b*" CMC:r1i1c>hwcfg partition=3 "r2i1b*" CMC:r1i1c>hwcfg partition=4 "r2i2b*"
Use the config -v command to show the four partitions, as follows:
CMC:r1i1c> config -v CMCs: 4 r001i01c UV1000 SMN r001i02c UV1000 r002i01c UV1000 r002i02c UV1000 BMCs: 64 r001i01b00 IP93-BASEIO P001 r001i01b01 IP93-DISK P001 r001i01b02 IP93-INTPCIE P001 r001i01b03 IP93 P001 r001i01b04 IP93 P001 r001i01b05 IP93 P001 r001i01b06 IP93 P001 r001i01b07 IP93 P001 r001i01b08 IP93 P001 r001i01b09 IP93-INTPCIE P001 r001i01b10 IP93-INTPCIE P001 r001i01b11 IP93-INTPCIE P001 r001i01b12 IP93-INTPCIE P001 r001i01b13 IP93 P001 r001i01b14 IP93 P001 r001i01b15 IP93 P001 r001i02b00 IP93-BASEIO P002 r001i02b01 IP93-DISK P002 r001i02b02 IP93-INTPCIE P002 r001i02b03 IP93 P002 r001i02b04 IP93 P002 r001i02b05 IP93 P002 r001i02b06 IP93 P002 r001i02b07 IP93 P002 r001i02b08 IP93 P002 r001i02b09 IP93 P002 r001i02b10 IP93 P002 r001i02b11 IP93 P002 r001i02b12 IP93 P002 r001i02b13 IP93 P002 r001i02b14 IP93 P002 r001i02b15 IP93 P002 r002i01b00 IP93-BASEIO P003 r002i01b01 IP93-DISK P003 r002i01b02 IP93 P003 r002i01b03 IP93 P003 r002i01b04 IP93 P003 r002i01b05 IP93 P003 r002i01b06 IP93 P003 r002i01b07 IP93 P003 r002i01b08 IP93 P003 r002i01b09 IP93 P003 r002i01b10 IP93 P003 r002i01b11 IP93 P003 r002i01b12 IP93 P003 r002i01b13 IP93 P003 r002i01b14 IP93 P003 r002i01b15 IP93 P003 r002i02b00 IP93-BASEIO P004 r002i02b01 IP93-DISK P004 r002i02b02 IP93 P004 r002i02b03 IP93 P004 r002i02b04 IP93 P004 r002i02b05 IP93 P004 r002i02b06 IP93 P004 r002i02b07 IP93 P004 r002i02b08 IP93 P004 r002i02b09 IP93 P004 r002i02b10 IP93 P004 r002i02b11 IP93 P004 r002i02b12 IP93 P004 r002i02b13 IP93 P004 r002i02b14 IP93 P004 r002i02b15 IP93 P004 Partitions: 4 partition001 BMCs: 16 partition002 BMCs: 16 partition003 BMCs: 16 partition004 BMCs: 16
Use can also use the hwcfg command to display the four partitions, as follows:
CMC:r1i1c> hwcfg NL5_RATE=5.0 PARTITION=1 ................................................ 16/64 BMC(s) PARTITION=2 ................................................ 16/64 BMC(s) PARTITION=3 ................................................ 16/64 BMC(s) PARTITION=4 ................................................ 16/64 BMC(s)
To reset the system and boot the four partitions, use the following commands:
CMC:r1i1c> power on CMC:r1i1c> power reset "p*"

Note: In the power reset "p*" command, above, quotes are required to prevent shell expansion.
Use the uvcon command to open consoles to each partition and boot the partitions. Open a console to partition one, as follows:
CMC:r1i1c> uvcon p1 uvcon: attempting connection to localhost... uvcon: connection to SMN/CMC (localhost) established. uvcon: requesting baseio console access at partition 1 (r001i01b00)... uvcon: tty mode enabled, use 'CTRL-]' 'q' to exit uvcon: console access established (OWNER) uvcon: CMC <--> BASEIO connection active ************************************************ ******* START OF CACHED CONSOLE OUTPUT ******* ************************************************ ******** [20100513.215944] BMC r001i01b15: Cold Reset via NL broadcast reset ******** [20100513.215944] BMC r001i01b07: Cold Reset via NL broadcast reset ******** [20100513.215945] BMC r001i01b13: Cold Reset via NL broadcast reset ******** [20100513.215945] BMC r001i01b05: Cold Reset via NL broadcast reset ******** [20100513.215945] BMC r001i01b06: Cold Reset via NL broadcast reset ******** [20100513.215946] BMC r001i01b10: Cold Reset via NL broadcast reset ******** [20100513.215946] BMC r001i01b09: Cold Reset via NL broadcast reset ******** [20100513.215945] BMC r001i01b11: Cold Reset via NL broadcast reset ******** [20100513.215945] BMC r001i01b12: Cold Reset via NL broadcast reset ******** [20100513.215945] BMC r001i01b04: Cold Reset via NL broadcast reset ******** [20100513.215945] BMC r001i01b08: Cold Reset via NL broadcast reset ******** [20100513.215946] BMC r001i01b02: Cold Reset via NL broadcast reset ******** [20100513.215945] BMC r001i01b00: Cold Reset via NL broadcast reset ******** [20100513.215945] BMC r001i01b14: Cold Reset via NL broadcast reset ******** [20100513.215947] BMC r001i01b09: Cold Reset via ICH ******** [20100513.215946] BMC r001i01b12: Cold Reset via ICH ******** [20100513.215947] BMC r001i01b10: Cold Reset via ICH ******** [20100513.215947] BMC r001i01b11: Cold Reset via ICH ******** [20100513.215947] BMC r001i01b02: Cold Reset via ICH ******** [20100513.215947] BMC r001i01b00: Cold Reset via ICH ******** [20100513.215953] BMC r001i01b03: Cold Reset via NL broadcast reset ******** [20100513.220011] BMC r001i01b01: Cold Reset via NL broadcast reset ******** [20100513.220012] BMC r001i01b08: Cold Reset via NL broadcast reset ******** [20100513.220012] BMC r001i01b07: Cold Reset via NL broadcast reset ******** [20100513.220011] BMC r001i01b15: Cold Reset via NL broadcast reset ******** [20100513.220012] BMC r001i01b06: Cold Reset via NL broadcast reset ******** [20100513.220012] BMC r001i01b05: Cold Reset via NL broadcast reset ******** [20100513.220012] BMC r001i01b14: Cold Reset via NL broadcast reset ******** [20100513.220012] BMC r001i01b13: Cold Reset via NL broadcast reset ******** [20100513.220011] BMC r001i01b04: Cold Reset via NL broadcast reset ******** [20100513.220012] BMC r001i01b03: Cold Reset via NL broadcast reset ******** [20100513.220013] BMC r001i01b09: Cold Reset via NL broadcast reset ******** [20100513.220013] BMC r001i01b10: Cold Reset via NL broadcast reset ******** [20100513.220013] BMC r001i01b11: Cold Reset via NL broadcast reset ******** [20100513.220012] BMC r001i01b12: Cold Reset via NL broadcast reset ******** [20100513.220012] BMC r001i01b02: Cold Reset via NL broadcast reset ******** [20100513.220012] BMC r001i01b00: Cold Reset via NL broadcast reset ******** [20100513.220014] BMC r001i01b09: Cold Reset via ICH ******** [20100513.220014] BMC r001i01b10: Cold Reset via ICH ******** [20100513.220014] BMC r001i01b11: Cold Reset via ICH ******** [20100513.220013] BMC r001i01b12: Cold Reset via ICH ******** [20100513.220013] BMC r001i01b02: Cold Reset via ICH ******** [20100513.220016] BMC r001i01b00: Cold Reset via ICH ******** [20100513.220035] BMC r001i01b14: Cold Reset via NL broadcast reset ******** [20100513.220035] BMC r001i01b06: Cold Reset via NL broadcast reset ******** [20100513.220034] BMC r001i01b15: Cold Reset via NL broadcast reset ******** [20100513.220035] BMC r001i01b05: Cold Reset via NL broadcast reset ******** [20100513.220034] BMC r001i01b01: Cold Reset via NL broadcast reset ******** [20100513.220035] BMC r001i01b07: Cold Reset via NL broadcast reset . . . . . . . . . . . . . . . . . . . .... Hit [Space] for Boot Menu. ELILO boot:
Note: Use the uvcon command to open consoles on the other three partitions and boot them. The system will then have four single system images.
Use the hwcfg -c partition command to clear the four partitions, as follows:
CMC:r1i1c> hwcfg -c partition PARTITION=0 PARTITION=0
Note: This will take several minutes on large systems.
To reset the system and boot it as a single system image (one partition), use the following command:
CMC:r1i1c> power reset "p*"
This section describes how to get Array Services operational on your system. For detailed information on Array Services, see chapter 3, “Array Sevices”, in the Linux Resource Administration Guide.
Standard Array Services is installed by default on an SGI ProPack 7 SP1 system. To install Secure Array Services, use the YaST Software Management and use the Filter->search function to search for secure array services by name (sarraysvcs).
To make Array Services operational on your system, perform the following steps:
| Note: Most of the steps to install array services is now performed automatically when the array services RPM is installed. To complete installation, perform the steps that follow. |
Make sure that the setting in the /usr/lib/array/arrayd.auth file is appropriate for your site.

Caution: Changing the AUTHENTICATION parameter from NOREMOTE to NONE may have a negative security impact on your site.
Make sure that the list of machines in your cluster is included in one or more array definitions in /usr/lib/array/arrayd.conf file.
To determine if Array Services is correctly installed, run the following command:
array who
You should see yourself listed.
Some applications can generate an excessive number of kernel KERN_WARN "floating point assist" warning messages. This section describes how you can make these messages disappear for specific applications or for specific users.
An application generates a "floating point assist" trap when a floating point operation involves a corner case of operand value(s) that the Itanium processor cannot handle in hardware and requires kernel emulation software to complete.
Sometimes the application can be recompiled with specific options that will avoid such problematic operand value(s). Using the -ffast-math option with gcc or the -ftz option with the Intel compiler might be effective. Other instances can be avoided by recoding the application to avoid denormalized or non-finite operands.
When recoding or recompiling is ineffective or infeasible, the user running the application or the system administrator can avoid having these "floating point assist" syslog messages appear by using the prctl(1) command, as follows:
% prctl --fpemu=silent command |
The command and every child process of the command invoked with prctl will produce no "floating point assist" messages. The command can be a single application that is producing unwanted syslog messages or it may be any shell script. For example, the "floating point assist" messages for the user as a whole, that is, for all applications that the user may execute, can be silenced by changing the /etc/passwd entry of the user to invoke a custom script at login, instead of executing (for instance) /bin/bash. That custom script then launches the user's high level shell using the following:
prctl --fpemu=silent /bin/bash |
Even if the syslog messages are silenced, the "assist" traps will continue to occur and the kernel software will still handle the problem. If these traps occur at a high enough frequency, the application performance may suffer and notification of these occurrences are not logged.
The syslog messages can be made to reappear by executing the prctl command again, as follows:
% prctl --fpemu=default command |
The section describes unaligned access warnings, as follows:
The kernel generated unaligned access warnings in syslog and on the console, when applications do misaligned loads and stores. This is normally a sign of badly written code and an indication that the application should be fixed.
Use the prctl(1) command to disable these messages on a per application basis.
SLES offers a new way allowing system administrators to disable these messages on a system wide basis. This is generally discouraged, but useful for the case where a system is used to run third-party applications which cannot be fixed by the system owner.
In order to disable these messages on a system wide level, do the following as root:
echo 1 > /proc/sys/kernel/ignore-unaligned-usertrap