Comprehensive System Accounting (CSA) provides detailed, accurate accounting data per job. It also provides data from some daemons. CSA typically runs with Linux kernel job. For more information on Linux kernel jobs, see Chapter 1, “Linux Kernel Jobs”. If you run CSA without Linux kernel jobs installed, no job accounting would be available.
The csarun(8) command, usually initiated by the cron(8) command, directs the processing of the CSA daily accounting files. The csarun (8) command processes accounting records written into the CSA accounting data file.
Using accounting data, you can determine how system resources were used and if a particular user has used more than a reasonable share; trace significant system events, such as security breaches, by examining the list of all processes invoked by a particular user at a particular time; and set up billing systems to charge login accounts for using system resources.
The Linux CSA application interface library allows software applications to manipulate and obtain status about Linux CSA accounting methods. For more information, see “ Linux CSA Application Interface Library” and “Linux CSA Application Interface Library” in Appendix B.
| Note: The CSA-3.0.0 version (or later) is a major cleanup of CSA and removes unsupported CSA record types, simplifies the /etc/csa.conf configuration file, and makes changes to header files. As a result of these changes, all user applications need to be recompiled. CSA-3.0.0 still supports accounting data files created in earlier version; however, CSA utilities from earlier releases can not read accounting data files created by CSA-3.0.0 and later. |
This chapter contains the following sections:
Comprehensive System Accounting (CSA) is a set of C programs and shell scripts that, like the other accounting packages, provide methods for collecting per-process resource usage data, monitoring disk usage, and charging fees to specific login accounts. CSA provides:
Per-job accounting
Daemon accounting (workload management systems and tape systems; note that tape daemon accounting is not supported in this release)
Flexible accounting periods (daily and periodic (monthly) accounting reports can be generated as often as desired and are not restricted to once per day or once per month)
Flexible system billing units (SBUs)
Offline archiving of accounting data
User exits for site specific customizing of daily and periodic (monthly) accounting
Configurable parameters within the /etc/csa.conf file
User job accounting (ja(1) command)
CSA takes this per-process accounting information and combines it by job identifier (jid) within system boot uptime periods. CSA accounting for a job consists of all accounting data for a given job identifier during a single system boot period. However, since workload management jobs may span multiple reboots and thereby consist of multiple job identifiers, CSA accounting for these jobs includes the accounting data associated with the workload management identifier. For this release, the workload managment identifier is yet to be defined.
Daemon accounting records are written at the completion of daemon specific events. These records are combined with per-process accounting records associated with the same job.
By default, CSA only reports accounting data for terminated jobs. Interactive jobs, cron jobs and at jobs terminate when the last process in the job exits, which is normally the login shell. A workload management job is recognized as terminated by CSA based upon daemon accounting records and an end-of-job record for that job. Jobs which are still active are recycled into the next accounting period. This behavior can be changed through use of the csarun command -A option.
A system billing unit (SBU) is a unit of measure that reflects use of machine resources. SBUs are defined in the CSA configuration file /etc/csa.conf and are set to 0.0 by default. The weighting factor associated with each field in the CSA accounting records can be altered to obtain an SBU value suitable for your site. For more information on SBUs, see “System Billing Units (SBUs)”.
The CSA accounting records are written into a separate CSA /var/csa/day/pacct file. The CSA commands can only be used with CSA generated accounting records.
There are four user exits available with the csarun(8) daily accounting script. There is one user exit available with the csaperiod (8) monthly accounting script. These user exits allow sites to tailor the daily and monthly run of accounting to their specific needs by creating user exit scripts to perform any additional processing and to allow archiving of accounting data. See the csarun(8) and csaperiod (8) man pages for further information. (User exits have not been defined for this release).
CSA provides two user accounting commands, csacom(1) and ja(1). The csacom command reads the CSA pacct file and writes selected accounting records to standard output. The ja command provides job accounting information for the current job of the caller. This information is obtained from a separate user job accounting file to which the kernel writes. See the csacom(1) and ja(1) man pages for further information.
“Workload Management Requests and Recycled Data”, contains information on cleaning up and maintaining workload management data files.
The /etc/csa.conf file contains CSA configuration variables. These variables are used by the CSA commands.
CSA is disabled in the kernel by default. To enable CSA, see “Enabling or Disabling CSA”.
The following concepts and terms are important to understand when using the accounting feature:
The following abbreviations and definitions are used throughout this chapter:
| Abbreviation | Definition | |
| MMDD | Month, day | |
| hhmm | Hour, minute |
The following steps are required to set up CSA job accounting:
Note: Before you configure CSA on your machine, make sure
that Linux jobs are installed and configured on your system. When you
run the jstat -a command, you should see output similar
to the following:
|
If jobs are not installed and configured, see “Installing and Configuring Linux Kernel Jobs for Use with CSA” in Chapter 1. For more information on the jstat command, see “Linux Kernel Job Overview” in Chapter 1 and the jstat(1) man page.
Configure CSA on across system reboots by using the chkconfig(8) command as follows:
chkconfig --add csa
Modify the CSA configuration variables in /etc/csa.conf as desired. Comments in the file describe these configuration options.
Turn on CSA, by entering the following:
/etc/init.d/csa start
This step will be done automatically for subsequent system reboots when CSA is configured on via the chkconfig(8) command.
For information on adding entries to the crontabs file so that the cron(1M) command automatically runs daily accounting, see “Setting Up CSA”.
The following steps are required to disable CSA job accounting:
To turn off CSA, enter the following:
/etc/init.d/csa stop
To stop CSA from initiating after a system reboot, enter the chkconfig command as follows:
chkconfig --del csa
The following sections describe the CSA files and directories.
The /var/csa directory contains CSA data and report files within various subdirectories. /var/csa contains data collection files used by CSA. CSA accesses pacct files to process system accounting data. The following diagram shows the directory and file layout for CSA:
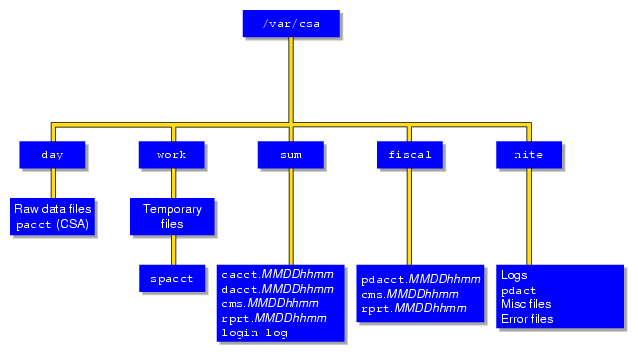
Each data and report file for CSA has a month-day-hour-minute suffix.
| Note: On an extremely busy system, the data contained under /var/csa can potentially reach the size of multiple Megabytes. If there are many CSA transactions, you may want to consider having /var/csa on a disk separate from root. |
The /var/csa directory contains the following directories:
| Directory | Description |
| day | Contains the current raw accounting data files in pacct format. |
| work | Used by CSA as a temporary work area. Contains raw files that were moved from /var/csa/day at the start of a CSA daily accounting run and the spacct file. |
| sum | Contains the cumulative daily accounting summary files and reports created by csarun(8). The ASCII format is in /var/csa/sum/rprt. MMDDhhmm. The binary data is in /var/csa/sum/cacct. MMDDhhmm, /var/csa/sum/cms.MMDDhhmm, and /var/csa/sum/dacct.MMDDhhmm . |
| fiscal | Contains periodic accounting summary files and reports created by csaperiod(8). The ASCII format is in /var/csa/fiscal/csa/rprt.MMDDhhmm . The binary data is in /usr/csa/fiscal/cms. MMDDhhmm and /usr/csa/fiscal/pdacct.MMDDhhmm . |
| nite | Contains log files, csarun state, and execution times files. |
The following files are located in the /var/csa/day directory:
The following files are located in the /var/csa/work/ MMDD/hhmm directory:
| File | Description | |||
| BAD.Wpacct* | Unprocessed accounting data containing invalid records (verified by csaverify(8)).
| |||
| Ever.tmp1 | Data verification work file. | |||
| Ever.tmp2 | Data verification work file. | |||
| Rpacct0 | Process and daemon accounting data to be recycled in the next accounting run. | |||
| Wdiskcacct | Disk accounting data (cacct.h format) created by dodisk(8) (see the dodisk(8) man page). | |||
| Wdtmp | Disk accounting data (ASCII) created by dodisk(8). | |||
| Wpacct* | Raw process and daemon accounting data.
| |||
| spacct | sorted pacct file |
The following data files are located in the /var/csa/sum directory:
| File | Description |
| cacct.MMDDhhmm | Consolidated daily data in cacct.h format. This file is deleted by csaperiod if the -r option is specified. |
| cms.MMDDhhmm | Daily command usage data in command summary (cms) record format. This file is deleted by csaperiod if the -r option is specified. |
| dacct.MMDDhhmm | Daily disk usage data in cacct.h format. This file is deleted by csaperiod if the -r option is specified. |
| loginlog | Login record file created by lastlogin. |
| rprt.MMDDhhmm | Daily accounting report. |
The following files are located in the /var/csa/fiscal directory:
| File | Description | |
| cms.MMDDhhmm | Periodic command usage data in command summary (cms) record format. | |
| pdacct.MMDDhhmm | Consolidated periodic data. | |
| rprt.MMDDhhmm | Periodic accounting report. |
The following files are located in the /var/csa/nite directory:
| File | Description | |
| active | Used by the csarun(8) command to record progress and print warning and error messages. active MMDDhhmm is the same as active after csarun detects an error. | |
| clastdate | Last two times csarun was executed; in MMDDhhmm format. | |
| dk2log | Diagnostic output created during execution of dodisk (see the cron entry for dodisk in “Setting Up CSA”). | |
| diskcacct | Disk accounting records in cacct.h format, created by dodisk. | |
| EaddcMMDDhhmm | Error/warning messages from the csaaddc(8) command for an accounting run done on MMDD at hhmm. | |
| Earc1MMDDhhmm | Error/warning messages from the csa.archive1(8) command for an accounting run done on MMDD at hhmm. | |
| Earc2MMDDhhmm | Error/warning messages from the csa.archive2(8) command for an accounting run done on MMDD at hhmm. | |
| Ebld.MMDDhhmm | Error/warning messages from the csabuild(8) command for an accounting run done on MMDD at hhmm. | |
| Ecmd.MMDDhhmm | Error/warning messages from the csacms(8) command when generating an ASCII report for an accounting run done on MMDD at hhmm. | |
| Ecms.MMDDhhmm | Error/warning messages from the csacms(8) command when generating binary data for an accounting run done on MMDD at hhmm. | |
| Econ.MMDDhhmm | Error/warning messages from the csacon(8) command for an accounting run done on MMDD at hhmm. | |
| Ecrep.MMDDhhmm | Error/warning messages from the csacrep(8) command for an accounting run done on MMDD at hhmm. | |
| Ecrpt.MMDDhhmm | Error/warning messages from the csacrep(8) command for an accounting run done on MMDD at hhmm. | |
| Edrpt.MMDDhhmm | Error/warning messages from the csadrep(8) command for an accounting run done on MMDD at hhmm. | |
| Erec.MMDDhhmm | Error/warning messages from the csarecy(8) command for an accounting run done on MMDD at hhmm. | |
| Euser.MMDDhhmm | Error/warning messages from the csa.user(8) user exit for an accounting run done on MMDD at hhmm. | |
| Epuser.MMDDhhmm | Error/warning messages from the csa.puser(8) user exit for an accounting run done on MMDD at hhmm. | |
| Ever.tmp1MMDDhhmm | Output file from invalid record offsets from the csaverify(8) command for an accounting run done on MMDD at hhmm. | |
| Ever.tmp2MMDDhhmm | Error/warning messages from the csaverify(8) command for an accounting run done on MMDD at hhmm. | |
| Ever.MMDDhhmm | Error/warning messages from the csaedit(8) and csaverify(8) command (from the Ever.tmp2 file) for an accounting run done on MMDD at hhmm. | |
| fd2log | Diagnostic output created during execution of csarun (see cron entry for csarun in “Setting Up CSA”). | |
| lock lock1 | Used to control serial use of the csarun(8) comand. | |
| pd2log | Diagnostic output created during execution of csaperiod (see cron entry for csaperiod in “Setting Up CSA”). | |
| pdact | Progress and status of csaperiod. pdact.MMDDhhmm is the same as pdact after csaperiod detects an error. | |
| statefile | Used to record current state during execution of the csarun command. |
The /usr/sbin directory contains the following commands and shell scripts used by CSA that can be executed individually or by cron(1):
| Command | Description | |
| csaaddc | Combines cacct records. | |
| csabuild | Organizes accounting records into job records. | |
| csachargefee | Charges a fee to a user. | |
| csackpacct | Checks the size of the CSA process accounting file. | |
| csacms | Summarizes command usage from per-process accounting records. | |
| csacon | Condenses records from the sorted pacct file. | |
| csacrep | Reports on consolidated accounting data. | |
| csadrep | Reports daemon usage. | |
| csaedit | Displays and edits the accounting information. | |
| csagetconfig | Searches the accounting configuration file for the specified argument. | |
| csajrep | Prints a job report from the sorted pacct file. | |
| csaperiod | Runs periodic accounting. | |
| csarecy | Recycles unfinished job records into next accounting run. | |
| csarun | Processes the daily accounting files and generates reports. | |
| csaswitch | Checks the status of, enables or disables the different types of Comprehensive System Accounting (CSA), and switches accounting files for maintainability. | |
| csaverify | Verifies that the accounting records are valid. |
The /usr/bin directory contains the following user commands associated with CSA:
| Command | Description | |
| csacom | Searches and prints the CSA process accounting files. | |
| ja | Starts and stops user job accounting information. |
User exits allow you to tailor the csarun or csaperiod procedures to the specific needs of your site by creating scripts to perform additional site-specific processing during daily accounting. You need to create user exit files owned by adm or csaacct (adm for SGI ProPack 3 and csaacct for SGI ProPack 4) with execute permission if your site uses the accounting user exits. User exits need to be recreated when you upgrade your system. For information on setting up user exits at your site and some example user exit scripts, see “Setting up User Exits”. The /usr/sbin directory may contain the following scripts
| Script | Description | |
| csa.archive1 | Site-generated user exit for csarun. This script saves off raw pacct data. | |
| csa.archive2 | Site-generated user exit for csarun. This script saves off sorted pacct data. | |
| csa.fef | Site-generated user exit for csarun. This script is written by an administrator for site-specific processing. | |
| csa.user | Site-generated user exit for csarun. This script is written by an administrator for site-specific processing. | |
| csa.puser | Site-generated user exit for csaperiod. This script is written by an administrator for site-specific processing. |
The /etc directory is the location of the csa.conf file that contains the parameter labels and values used by CSA software.
This section contains detailed information about CSA and covers the following topics:
When the Linux operating system is run in multiuser mode, accounting behaves in a manner similar to the following process. However, because sites may customize CSA, the following may not reflect the actual process at a particular site.
When CSA accounting is enabled and the system is switched to multiuser mode, the /usr/sbin/csaswitch (see the csaswitch(8) man page) command is called by /etc/init.d/csa.
By default, CPU, memory, and I/O record types are enabled in /etc/csa.conf. However, to run workload management and tape daemon accounting, you must modify the /etc/csa.conf file and the appropriate subsystem. For more information, see “Setting Up CSA”.
The amount of disk space used by each user is determined periodically. The /usr/sbin/dodisk command (see dodisk(8)) is run periodically by the cron command to generate a snapshot of the amount of disk space being used by each user. The dodisk command should be run at most once for each time /usr/sbin/csarun is run (see csarun(8)). Multiple invocations of dodisk during the same accounting period write over previous dodisk output.
A fee file is created. Sites desiring to charge fees to certain users can do so by invoking /usr/sbin/csachargefee (see csachargefee(8)). Each accounting period's fee file (/var/csa/day/fee) is merged into the consolidated accounting records by /usr/sbin/csaperiod (see csaperiod(8)).
Daily accounting is run. At specified times during the day, csarun is executed by the cron command to process the current accounting data. The output from csarun is daily accounting files and an ASCII report.
Periodic (monthly) accounting is run. At a specific time during the day, or on certain days of the month, /usr/sbin/csaperiod (see csaperiod) is executed by the cron command to process consolidated accounting data from previous accounting periods. The output from csaperiod is periodic (monthly) accounting files and an ASCII report.
Accounting is disabled. When the system is shut down gracefully, the csaswitch(8) command is executed to halt all CSA process and daemon accounting.
The following is a brief description of setting up CSA. Site-specific modifications are discussed in detail in “Tailoring CSA”. As described in this section, CSA is run by a person with superuser permissions.
Change the default system billing unit (SBU) weighting factors, if necessary. By default, no SBUs are calculated. If your site wants to report SBUs, you must modify the configuration file /etc/csa.conf.
Modify any necessary parameters in the /etc/csa.conf file, which contains configurable parameters for the accounting system.
If you want daemon accounting, you must enable daemon accounting at system startup time by performing the following steps:
Ensure that the variables in /etc/csa.conf for the subsystems for which you want to enable daemon accounting are set to on.
Set WKMG_START to on to enable workload management.
As root, use the crontab (1) command with the -e option to add entries similar to the following:

Note: If you do not use the crontab(1) command to update the crontab file (for example, using the vi(1) editor to update the file), you must signal cron(8) after updating the file. The crontab command automatically updates the crontab file and signals cron(8) when you save the file and exit the editor. For more information on the crontab command, see the crontab(1) man page.
0 4 * * 1-6 if /sbin/chkconfig csa; then /usr/sbin/csarun 2> /var/csa/nite/fd2log; fi 0 2 * * 4 if /sbin/chkconfig csa; then /usr/sbin/dodisk > /var/csa/nite/dk2log; fi 5 * * * 1-6 if /sbin/chkconfig csa; then /usr/sbin/csackpacct; fi 0 5 1 * * if /sbin/chkconfig csa; then /usr/sbin/csaperiod -r \ 2> /var/csa/nite/pd2log; fi
These entries are described in the following steps:
For most installations, entries similar to the following should be made in /var/spool/cron/root so that cron(8) automatically runs daily accounting:
0 4 * * 1-6 if /sbin/chkconfig csa; then /usr/sbin/csarun 2> /var/csa/nite/fd2log; fi 0 2 * * 4 if /sbin/chkconfig csa; then /usr/sbin/dodisk > /var/csa/nite/dk2log; fi
The csarun(8) command should be executed at such a time that dodisk has sufficient time to complete. If dodisk does not complete before csarun executes, disk accounting information may be missing or incomplete.
For more information, see the dodisk(8) man page.
Periodically check the size of the pacct files. An entry similar to the following should be made in /var/spool/cron/root:
5 * * * 1-6 if /sbin/chkconfig csa; then /usr/sbin/csackpacct; fi
The cron command should periodically execute the csackpacct(8) shell script. If the pacct file grows larger than 4000 1K blocks (default), csackpacct calls the command /usr/sbin/csaswitch -c switch to start a new pacct file. The csackpacct command also makes sure that there are at least 2000 1KB blocks free on the file system containing /var/csa. If there are not enough blocks, CSA accounting is turned off. The next time csackpacct is executed, it turns CSA accounting back on if there are enough free blocks.
Ensure that the ACCT_FS and MIN_BLKS variables have been set correctly in the /etc/csa.conf configuration file. ACCT_FS is the file system containing /var/csa. MIN_BLKS is the minimum number of free 1K blocks needed in the ACCT_FS file system. The default is 2000.
It is very important that csackpacct be run periodically so that an administrator is notified when the accounting file system (located in the /var/csa directory by default) runs out of disk space. After the file system is cleaned up, the next invocation of csackpacct enables process and daemon accounting. You can manually re-enable accounting by invoking csaswitch -c on.
If csackpacct is not run periodically, and the accounting file system runs out of space, an error message is written to the console stating that a write error occurred and that accounting is disabled. If you do not free disk space as soon as possible, a vast amount of accounting data can be lost unnecessarily. Additionally, lost accounting data can cause csarun to abort or report erroneous information.
To run monthly accounting, an entry similar to the command shown below should be made in /var/spool/cron/root . This command generates a monthly report on all consolidated data files found in /var/csa/sum/* and then deletes those data files:
0 5 1 * * if /sbin/chkconfig csa; then /usr/sbin/csaperiod -r \ 2> /var/csa/nite/pd2log; fi
This entry is executed at such a time that csarun has sufficient time to complete. This example results in the creation of a periodic accounting file and report on the first day of each month. These files contain information about the previous month's accounting.
Update the holidays file. The holidays file allows you to adust the price of system resources depending on expected demand. The file /usr/local/etc/holidays contains the prime/nonprime table for the accounting system. The table should be edited to reflect your location's holiday schedule for the year. By default, the holidays file is located in the /usr/local/etc directory. You can change this location by modifying the HOLIDAY_FILE variable in /etc/csa.conf. If necessary, modify the NUM_HOLIDAYS variable (also located in /etc/csa.conf), which sets the upper limit on the number of holidays that can be defined in HOLIDAY_FILE . The format of this file is composed of the following types of entries:
Comment lines: These lines may appear anywhere in the file as long as the first character in the line is an asterisk (*).
Version line: This line must be the first uncommented line in the file and must only appear once. It denotes that the new holidays file format is being used. This line should not be changed by the site.
Year designation line: This line must be the second uncommented line in the file and must only appear once. The line consists of two fields. The first field is the keyword YEAR. The second field must be either the current year or the wildcard character, asterisk (*). If the year is wildcarded, the current year is automatically substituted for the year. The following are examples of two valid entries:
YEAR 2003 YEAR *
Prime/nonprime time designation lines: These must be uncommented lines 3, 4, and 5 in the file. The format of these lines is:
period prime_time_start nonprime_time_start
The variable, period, is one of the following: WEEKDAY, SATURDAY, or SUNDAY. The period can be specified in either uppercase or lowercase.
The prime and nonprime start time can be one of two formats:
Both start times are 4-digit numeric values between 0000 and 2359. The nonprime_time_start value must be greater than the prime_time_start value. For example, it is incorrect to have prime time start at 07:30 A.M. and nonprime time start at 1 minute after midnight. Therefore, the following entry is wrong and can cause incorrect accounting values to be reported.
WEEKDAY 0730 0001
It is correct to specify prime time to start at 07:30 A.M. and nonprime time to start at 5:30 P.M. on weekdays. You would enter the following in the holiday file:
WEEKDAY 0730 1730
NONE/ALL or ALL/NONE. These start times specify that the entire period is to be either all prime time or all nonprime time. To specify that the entire period is to be considered prime time, set prime_time_start to ALL and nonprime_time_start to NONE. If the period is to be considered all nonprime time, set prime_time_start to NONE and nonprime_time_start to ALL. For example, to specify Monday through Friday as all prime time, you would enter the following:
WEEKDAY ALL NONE
To specify all of Sunday to be nonprime time, you would enter the following:
SUNDAY NONE ALL
Site holidays lines: These entries follow the year designation line and have the following general format:
day-of-year Month Day Description of Holiday
The day-of-year field is either a number in the range of 1 through 366, indicating the day for a given holiday (leading white space is ignored), or it is the month and day in the mm/dd format. The other three fields are commentary and are not currently used by other programs. Each holiday is considered all nonprime time.
If the holidays file does not exist or there is an error in the year designation line, the default values for all lines are used.
If there is an error in a prime/nonprime time designation line, the entry for the erroneous line is set to a default value. All other lines in the holidays file are ignored and default values are used.
If there is an error in a site holidays line, all holidays are ignored.
The defaults values are as follows:
YEAR The current year
WEEKDAY Monday through Friday is all prime time
SATURDAY Saturday is all nonprime time
SUNDAY Sunday is all nonprime time
No holidays are specified
The /usr/sbin/csarun command, usually initiated by cron(1), directs the processing of the daily accounting files. csarun processes accounting records written into the pacct file. It is normally initiated by cron during nonprime hours.
The csarun command also contains four user-exit points, allowing sites to tailor the daily run of accounting to their specific needs.
The csarun command does not damage files in the event of errors. It contains a series of protection mechanisms that attempt to recognize an error, provide intelligent diagnostics, and terminate processing in such a way that csarun can be restarted with minimal intervention.
The csarun command is invoked periodically by cron. It is very important that you ensure that the previous invocation of csarun completed successfully before invoking csarun for a new accounting period. If this is not done, information about unfinished jobs will be inaccurate.
Data for a new accounting period can also be interactively processed by executing the following:
nohup csarun 2> /var/csa/nite/fd2log & |
Before executing csarun in this manner, ensure that the previous invocation completed successfully. To do this, look at the files active and statefile in /var/csa/nite. Both files should specify that the last invocation completed successfully. See “Restarting csarun”.
The csarun error and status messages are placed in the /var/csa/nite directory. The progress of a run is tracked by writing descriptive messages to the file active. Diagnostic output during the execution of csarun is written to fd2log. The lock and lock1 files prevent concurrent invocations of csarun; csarun will abort if these two files exist when it is invoked. The clastdate file contains the month, day, and time of the last two executions of csarun.
Errors and warning messages from programs called by csarun are written to files that have names beginning with E and ending with the current date and time. For example, Ebld.11121400 is an error file from csabuild for a csarun invocation on November 12, at 14:00.
If csarun detects an error, it writes a message to the /var/log/messages file, removes the locks, saves the diagnostic files, and terminates execution. When csarun detects an error, it will send mail either to MAIL_LIST if it is a fatal error, or to WMAIL_LIST if it is a warning message, as defined in the configuration file /etc/csa.conf .
Processing is broken down into separate re-entrant states so that csarun can be restarted. As each state completes, /var/csa/nite/statefile is updated to reflect the next state. When csarun reaches the CLEANUP state, it removes various data files and the locks, and then terminates.
The following describes the events that occur in each state. MMDD refers to the month and day csarun was invoked. hhmm refers to the hour and minute of invocation.
| State | Description |
| SETUP | The current accounting file is switched via csaswitch. The accounting file is then moved to the /var/csa/work/MMDD/hhmm directory. File names are prefaced with W. /var/csa/nite/diskcacct is also moved to this directory. |
| VERIFY | The accounting files are checked for valid data. Records with invalid data are removed. Names of bad data files are prefixed with BAD. in the /var/csa/work/ MMDD/hhmm directory. The corrected files do not have this prefix. |
| ARCHIVE1 | First user exit of the csarun script. If a script named /usr/sbin/csa.archive1 exists, it will it will be sourced by the shell using the shell . (dot) command. The . (dot) command will not execute a compiled program, but the user exit script can. You might use this user exit to archive the accounting files in ${WORK}. |
| BUILD | The pacct accounting data is organized into a sorted pacct file. |
| ARCHIVE2 | Second user exit of the csarun script. If a script named /usr/sbin/csa.archive2 exists, it will be executed through the shell . (dot) command. The . (dot) command will not execute a compiled program, but the user exit script can. You might use this exit to archive the sorted pacct file. |
| CMS | Produces a command summary file in cms.h format. The cms file is written to /var/csa/sum/cms.MMDDhhmm for use by csaperiod. |
| REPORT | Generates the daily accounting report and puts it into /var/csa/sum/rprt.MMDDhhmm. A consolidated data file, /var/csa/sum/cacct. MMDDhhmm, is also produced from the sorted pacct file. In addition, accounting data for unfinished jobs is recycled. |
| DREP | Generates a daemon usage report based on the sorted pacct file. This report is appended to the daily accounting report, /var/csa/sum/rprt.MMDDhhmm . |
| FEF | Third user exit of the csarun script. If a script named /var/local/sbin/csa.fef exists, it will be executed through the shell . (dot) command. The . (dot) command will not execute a compiled program, but the user exit script can. The csarun variables are available, without being exported, to the user exit script. You might use this exit to convert the sorted pacct file to a format suitable for a front-end system. |
| USEREXIT | Fourth user exit of the csarun script. If a script named /usr/sbin/csa.user exists, it will be executed through the shell . (dot) command. The . (dot) command will not execute a compiled program, but the user exit script can. The csarun variables are available, without being exported, to the user exit script. You might use this exit to run local accounting programs. |
| CLEANUP | Cleans up temporary files, removes the locks, and then exits. |
If csarun is executed without arguments, the previous invocation is assumed to have completed successfully.
The following operands are required with csarun if it is being restarted:
csarun [MMDD [hhmm [state]]] |
MMDD is month and day, hhmm is hour and minute, and state is the csarun entry state.
To restart csarun, follow these steps:
Remove all lock files, by using the following command line:
rm -f /var/csa/nite/lock*
Execute the appropriate csarun restart command, using the following examples as guides:
To restart csarun using the time and the state specified in clastdate and statefile, execute the following command:
nohup csarun 0601 2> /var/csa/nite/fd2log &
In this example, csarun will be rerun for June 1, using the time and state specified in clastdate and statefile.
To restart csarun using the state specified in statefile, execute the following command:
nohup csarun 0601 0400 2> /var/csa/nite/fd2log &
In this example, csarun will be rerun for the June 1 invocation that started at 4:00 A.M., using the state found in statefile.
To restart csarun using the specified date, time, and state, execute the following command:
nohup csarun 0601 0400 BUILD 2> /var/csa/nite/fd2log &
In this example, csarun will be restarted for the June 1 invocation that started at 4:00 A.M., beginning with state BUILD.
Before csarun is restarted, the appropriate directories must be restored. If the directories are not restored, further processing is impossible. These directories are as follows:
/var/csa/work/MMDD/hhmm /var/csa/sum |
If you are restarting at state ARCHIVE2, CMS, REPORT, DREP, or FEF , the sorted pacct file must be in /var/csa/work/MMDD/hhmm. If the file does not exist, csarun automatically will restart at the BUILD state. Depending on the tasks performed during the site-specific USEREXIT state, the sorted pacct file may or may not need to exist. This may or may not be acceptable.
This section describes how to remove bad data from various accounting files.
The csaverify (8) command verifies that the accounting records are valid and identifies invalid records. The accounting file can be a pacct or sorted pacct file. When csaverify finds an invalid record, it reports the starting byte offset and length of the record. This information can be written to a file in addition to standard output. A length of -1 indicates the end of file. The resulting output file can be used as input to csaedit(8) to delete pacct or sorted pacct records.
The pacct file is verified with the following command line, and the following output is received:
$ /usr/sbin/csaverify -P pacct -o offsetfile /usr/sbin/csaverify: CAUTION readacctent(): An error was returned from the 'readpacct()' routine.
The file offsetfile from csaverify is used as input to csaedit to delete the invalid records as follows (remaining valid records are written to pacct.NEW):
/usr/sbin/csaedit -b offsetfile -P pacct -o pacct.NEW
The new pacct file is reverified as follows to ensure that all the bad records have been deleted:
/usr/sbin/csaverify -P pacct.NEW
You can use the csaedit -A option to produce an abbreviated ASCII version of pacct or sorted pacct files.
The flow of data among the various CSA programs is explained in this section and is illustrated in Figure 2-2.
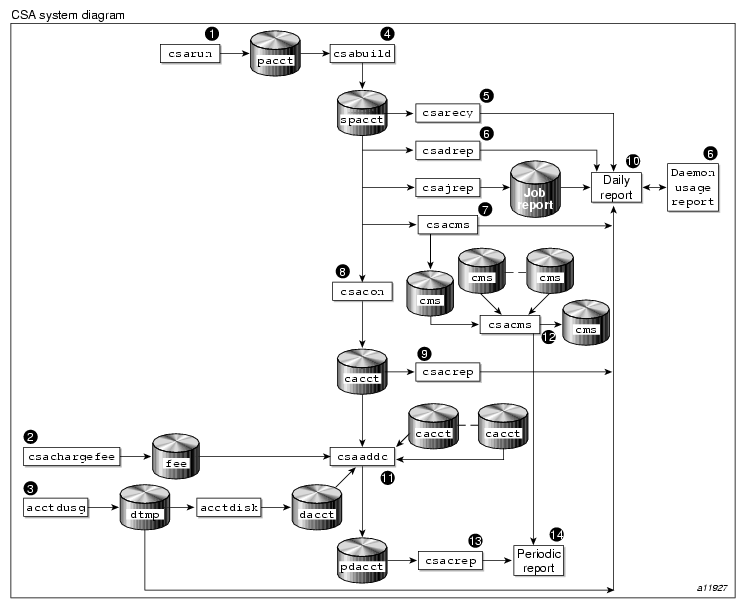
Generate raw accounting files. Various daemons and system processes write to the raw pacct accounting files.
Create a fee file. Sites that want to charge fees to certain users can do so with the csachargefee(8) command. The csachargefee command creates a fee file that is processed by csaaddc(8).
Produce disk usage statistics. The dodisk (8) shell script allows sites to take snapshots of disk usage. dodisk does not report dynamic usage; it only reports the disk usage at the time the command was run. Disk usage is processed by csaaddc.
Organize accounting records into job records. The csabuild(8) command reads accounting records from the CSA pacct file and organizes them into job records by job ID and boot times. It writes these job records into the sorted pacct file. This sorted pacct file contains all of the accounting data available for each job. The configuration records in the pacct files are associated with the job ID 0 job record within each boot period. The information in the sorted pacct file is used by other commands to generate reports and for billing.
Recycle information about unfinished jobs. The csarecy(8) command retrieves job information from the sorted pacct file of the current accounting period and writes the records for unfinished jobs into a pacct0 file for recycling into the next accounting period. csabuild(8) marks unfinished accounting jobs (those are jobs without an end-of-job record). csarecy takes these records from the sorted pacct file and puts them into the next period's accounting files directory. This process is repeated until the job finishes.
Sometimes data for terminated jobs are continually recycled. This can occur when accounting data is lost. To prevent data from recycling forever, edit csarun so that csabuild is executed with the -o nday option, which causes all jobs older than nday days to terminate. Select an appropriate nday value (see the csabuild man page for more information and “Data Recycling”).
Generate the daemon usage report, which is appended to the daily report. csadrep(8) reports usage of the workload management and tape (tape is not supported in this release) daemons. Input is either from a sorted pacct file created by csabuild(8) or from a binary file created by csadrep with the -o option. The files operand specifies the binary files.
Summarize command usage from per-process accounting records. The csacms(8) command reads the sorted pacct files. It adds all records for processes that executed identically named commands, and it sorts and writes them to /var/csa/sum/cms.MMDDhhmm, using the cms format. The csacms(8) command can also create an ASCII file.
Condense records from the sorted pacct file. The csacon(8) command condenses records from the sorted pacct file and writes consolidated records in cacct format to /var/csa/sum/cacct.MMDDhhmm.
Generate an accounting report based on the consolidated data. The csacrep(8) command generates reports from data in cacct format, such as output from the csacon(8) command. The report format is determined by the value of CSACREP in the /etc/csa.conf file. Unless modified, it will report the CPU time, total KCORE minutes total KVIRTUAL minutes, block I/O wait time, and raw I/O wait time. The report will be sorted first by user ID and then by the secondary key of project ID (project ID is not supported in this release) and the headers will be printed.
Create the daily accounting report. The daily accounting report includes the following:
Consolidated information report (step 11)
Unfinished recycled jobs (step 5)
Disk usage report (step 3)
Daily command summary (step 7)
Last login information
Daemon usage report (step 6)
Combine cacct records. The csaaddc(8) command combines cacct records by specified consolidation options and writes out a consolidated record in cacct format.
Summarize command usage from per-process accounting records. The csacms(8) command reads the cms files created in step 7. Both an ASCII and a binary file are created.
Produce a consolidated accounting report. csacrep(8) is used to generate a report based on a periodic accounting file.
The periodic accounting report layout is as follows:
Consolidated information report
Command summary report
Steps 4 through 11 are performed during each accounting period by csarun(8). Periodic (monthly) accounting (steps 12 through 14) is initiated by the csaperiod(8) command. Daily and periodic accounting, as well as fee and disk usage generation (steps 2 through 3), can be scheduled by cron(8) to execute regularly. See “Setting Up CSA”, for more information.
A system administrator must correctly maintain recycled data to ensure accurate accounting reports. The following sections discuss data recycling and describe how an administrator can purge unwanted recycled accounting data.
Data recycling allows CSA to properly bill jobs that are active during multiple accounting periods. By default, csarun reports data only for jobs that terminate during the current accounting period. Through data recycling, CSA preserves data for active jobs until the jobs terminate.
In the sorted pacct file, csabuild flags each job as being either active or terminated. csarecy reads the sorted pacct file and recycles data for the active jobs. csacon consolidates the data for the terminated jobs, which csaperiod uses later. csabuild, csarecy, and csacon are all invoked by csarun.
The csarun command puts recycled data in the /var/csa/day/pacct0 file.
Normally, an administrator should not have to manually purge the recycled accounting data. This purge should only be necessary if accounting data is missing. Missing data can cause jobs to recycle forever and consume valuable CPU cycles and disk space.
Interactive jobs, cron jobs, and at jobs terminate when the last process in the job exits. Normally, the last process to terminate is the login shell. The kernel writes an end-of-job (EOJ) record to the pacct file when the job terminates.
When the workload management daemon delivers a workload management request's output, the request terminates. The daemon then writes an NQ_DISP record type to the pacct accounting file, while the kernel writes an EOJ record to the pacct file.
Unlike interactive jobs, workload management requests can have multiple EOJ records associated with them. In addition to the request's EOJ record, there can be EOJ records for net clients and checkpointed portions of the request. The net client perform workload management processing on behalf of the request.
The csabuild command flags jobs in the sorted pacct file as being terminated if they meet one of the following conditions:
The job is an interactive, cron, or at job, and there is an EOJ record for the job in the pacct file.
The job is a workload management request, and there is both an EOJ record for the request and an NQ_DISP record type in the pacct file.
The job is an interactive, cron, or at job and is active at the time of a system crash. (Note that for this release jobs can not be restarted).
The job is manually terminated by the administrator using one of the methods described in “How to Remove Recycled Data”.
Recycling unnecessary data can consume large amounts of disk space and CPU time. The sorted pacct file and recycled data can occupy a vast amount of disk space on the file system containing /var/csa/day. Sites that archive data also require additional offline media. Wasted CPU cycles are used by csarun to reexamine and recycle the data. Therefore, to conserve disk space and CPU cycles, unnecessary recycled data should be purged from the accounting system.
Any of the following situations can cause CSA erroneously to recycle terminated jobs:
Kernel or daemon accounting is turned off.
The kernel or csackpacct(8) command can turn off accounting when there is not enough space on the file system containing /var/csa/day.
Accounting files are corrupt. Accounting data can be lost or corrupted during a system or disk crash.
Recycled data is erroneously deleted in a previous accounting period.
Before choosing to delete recycled data, you should understand the repercussions, as described in “Adverse Effects of Removing Recycled Data”. Data removal can affect billing and can alter the contents of the consolidated data file, which is used by csaperiod.
You can remove recycled data from CSA in the following ways:
Interactively execute the csarecy-A command. Administrators can select the active jobs that are to be recycled by running csarecy with the -A option. Users are not billed for the resources used in the jobs terminated in this manner. Deleted data is also not included in the consolidated data file.
The following example is one way to execute csarecy-A (which generates two accounting reports and two consolidated files):
Run csarun at the regularly scheduled time.
Edit a copy of /usr/sbin/csarun. Change the -r option on the csarecy invocation line to -A. Also, do not redirect standard output to ${SUM_DIR}/recyrpt. The result should be similar to the following:
csarecy -A -s ${SPACCT} -P ${WTIME_DIR}/Rpacct \ 2> ${NITE_DIR}/Erec.${DTIME}Since both the -A and -r options write output to stdout, the -r option is not invoked and stdout is not redirected to a file. As a result, the recycled job report is not generated.
Execute the jstat command, as follows, to display a list of currently active jobs:
jstat -a > jstat.out
Execute the qstat command to display a list of workload management requests. The qstat command is used for seeing whether there are requests that are not currently running. This includes requests that are checkpointed, held, queued, or waiting.
To list all workload management requests, execute the qstat command, as follows, using a login that has either workload management manager or workload management operator privilege:
qstat -a > qstat.out
Interactively run the modified version of csarun. If you execute the modified csarun soon after the first step is complete, little data is lost because not very much data exists.
For each active job, csarecy asks you if you want to preserve the job. Preserve the active and nonrunning workload management jobs found in the third and fourth steps. All other jobs are candidates for removal.
Execute csabuild with the -ondays option, which terminates all active jobs older than the specified number of days. Resource usage for these terminated jobs is reported by csarun , and users are billed for the jobs. The consolidated data file also includes this resource usage.
To execute csabuild with the -o option, edit a copy of /usr/sbin/csarun. Add the -ondays option to the csabuild invocation line. Specify for ndays an appropriate value for your site.
Recycled data for currently active jobs will be removed if you specify an inappropriate value for ndays.
Execute csarun with the -A option. It reports resource usage for both active and terminated jobs, so users are billed for recycled sessions. This data is also included in the consolidated data file.
None of the data for the active jobs, including the currently active jobs, is recycled. No recycled data file is generated in the /var/csa/day directory.
Remove the recycled data file from the /var/csa/day directory. You can delete data for all of the recycled jobs, both terminated and active, by executing the following command:
rm /var/csa/day/pacct0
The next time csarun is executed, it will not find data for any recycled jobs. Thus, users are not billed for the resources used in the recycled jobs, and this data is not included in the consolidated data file. csarun recycles the data for currently active jobs.
CSA assumes that all necessary accounting information is available to it, which means that CSA expects kernel and daemon accounting to be enabled and recycled data not to have been mistakenly removed. If some data is unavailable, CSA may provide erroneous billing information. Sites should be aware of the following facts before removing data:
Users may or may not be billed for terminated recycled jobs. Administrators must understand which of the previously described methods cause the user to be billed for the terminated recycled jobs. It is up to the site to decide whether or not it is valid for the user to be billed for these jobs.
For those methods that cause the user to be billed, both csarun and csaperiod report the resource usage.
It may be impossible to reconstruct a terminated recycled job. If a recycled job is terminated by the administrator, but the job actually terminates in a later accounting period, information about the job is lost. If a user questions the resource billing, it may be extremely difficult or impossible for the administrator to correctly reassemble all accounting information for the job in question.
Manually terminated recycled jobs may be improperly billed in a future billing period. If the accounting data for the first portion of a job has been deleted, CSA may be unable to correctly identify the remaining portion of the job. Errors may occur, such as workload management requests being flagged as interactive jobs, or workload management requests being billed at the wrong queue rate. This is explained in detail in “Workload Management Requests and Recycled Data”.
CSA programs may detect data inconsistencies. When accounting data is missing, CSA programs may detect errors and abort.
The following table summarizes the effects of using the methods described in “How to Remove Recycled Data”.
Table 2-1. Possible Effects of Removing Recycled Data
Method | Underbilling? | Incorrect billing? | Consolidated data file |
|---|---|---|---|
csarecy -A | Yes. Users are not billed for the portion of the job that was terminated by csarecy-A. | Possible. Manually terminated recycled jobs may be billed improperly in a future billing period. | Does not include data for jobs terminated by csarecy-A. |
csabuild -o | No. Users are billed for the portion of the job that was terminated by csabuild-o. | Possible. Manually terminated recycled jobs may be billed improperly in a future billing period. | Includes data for jobs terminated by csabuild-o. |
csarun -A | No. All active and recycled jobs are billed. | Possible. All active and recycled jobs that eventually terminate may be billed improperly in a future billing period, because no data is recycled. | Includes data for all active and recycled jobs. |
rm | Yes. All users are not billed for the portion of the job that was recycled. | Possible. All recycled jobs that eventually terminate may be billed improperly in a future billing period. | Does not include data for any recycled job. |
By default, the consolidated data file contains data only for terminated jobs. Manual termination of recycled data may cause some of the recycled data to be included in the consolidated file.
For CSA to identify all workload management requests, data must be properly recycled. When an administrator manually purges recycled data for a workload management request, errors such as the following can occur:
CSA fails to flag the job as a workload management job. This causes the request to be billed at standard rates instead of a workload management queue rate (see “Workload Management SBUs”).
The request is billed at the wrong queue rate.
The wrong queue wait time is associated with the request.
These errors occur because valuable workload management accounting information was purged by the administrator. Only a few workload management accounting records are written by the workload management daemon, and all of the records are needed for CSA to properly bill workload management requests.
Workload management accounting records are only written under the following circumstances:
The workload management daemon receives a request.
A request executes. This includes executing a request for the first time, restarting, and rerunning a request.
A request terminates. A workload management request can terminate because it is completed, requeued, held, rerun, or migrated.
Output is delivered.
Thus, for long running requests that span days, there can be days when no workload management data is written. Consequently, it is extremely important that accounting data be recycled. If the site administrator manually terminates recycled jobs, care must be taken to be sure that only nonexistent workload management requests are terminated.
This section describes the following actions in CSA:
Setting up SBUs
Setting up daemon accounting
Setting up user exits
Modifying the charging of workload management jobs based on workload management termination status
Tailoring CSA shell scripts
Using at(1) instead of cron(8) to periodically execute csarun
Allowing users without superuser permissions to run CSA
Using an alternate configuration file
A system billing unit (SBU) is a unit of measure that reflects use of machine resources. You can alter the weighting factors associated with each field in each accounting record to obtain an SBU value suitable for your site. SBUs are defined in the accounting configuration file, /etc/csa.conf . By default, all SBUs are set to 0.0.
Accounting allows different periods of time to be designated either prime or nonprime time (the time periods are specified in /usr/sbin/holidays).
Following is an example of how the prime/nonprime algorithm works:
Assume a user uses 10 seconds of CPU time, and executes for 100 seconds of prime wall-clock time, and pauses for 100 seconds of nonprime wall-clock time. Therefore, elapsed time is 200 seconds (100+100). If
prime = prime time / elapsed time nonprime = nonprime time / elapsed time cputime[PRIME] = prime * CPU time cputime[NONPRIME] = nonprime * CPU time |
then
cputime[PRIME] == 5 seconds cputime[NONPRIME] == 5 seconds |
Under CSA, an SBU value is associated with each record in the sorted pacct file when that file is assembled by csabuild. Final summation of the SBU values is done by csacon during the creation of the cacct record file.
The following examples show how a site can bill different NQS or workload management queues at differing rates:
Total SBU = (Workload management queue SBU value) * (sum of all process record SBUs
+ sum of all tape record SBUs) |
The SBUs for process data are separated into prime and nonprime values. Prime and nonprime use is calculated by a ratio of elapsed time. If you do not want to make a distinction between prime and nonprime time, set the nonprime time SBUs and the prime time SBUs to the same value. Prime time is defined in /usr/local/etc/holidays. By default, Saturday and Sunday are considered nonprime time.
The following is a list of prime time process SBU weights. Descriptions and factor units for the nonprime time SBU weights are similar to those listed here. SBU weights are defined in /etc/csa.conf.
| Value | Description | |
| P_BASIC | Prime-time weight factor. P_BASIC is multiplied by the sum of prime time SBU values to get the final SBU factor for the process record. | |
| P_TIME | General-time weight factor. P_TIME is multiplied by the time SBUs (made up of P_STIME, P_UTIME, P_QTIME, P_BWTIME, and P_RWTIME) to get the time contribution to the process record SBU value. | |
| P_STIME | System CPU-time weight factor. The unit used for this weight is billing units per second. P_STIME is multiplied by the system CPU time. | |
| P_UTIME | User CPU-time weight factor. The unit used for this weight is billing units per second. P_UTIME is multiplied by the user CPU time. | |
| P_BWTIME | Block I/O wait time weight factor. The unit used for this weight is billing units per second. P_BWTIME is multiplied by the block I/O wait time. | |
| P_RWTIME | Raw I/O wait time weight factor. The unit used for this weight is billing units per second. P_RWTIME is multiplied by the raw I/O wait time. | |
| P_MEM | General-memory-integral weight factor. P_MEM is multiplied by the memory SBUs (made up of P_XMEM and P_VMEM) to get the memory contribution to the process record SBU value. | |
| P_XMEM | CPU-time-core-physical memory-integral weight factor. The unit used for this weight is billing units per Mbyte-minute P_XMEM is multiplied by the core-memory integral. | |
| P_VMEM | CPU-time-virtual-memory-integral weight factor. The unit used for this weight is billing units per Mbyte-minute. P_VMEM is multiplied by the virtual memory integral. | |
| P_IO | General-I/O weight factor. P_IO is multiplied by the I/O SBUs (made up of P_BIO, P_CIO, and P_LIO) to get the I/O contribution to the process record SBU value. | |
| P_BIO | Blocks-transferred weight factor. The unit used for this weight is billing units per block transferred. P_BIO is multiplied by the number of I/O blocks transferred. | |
| P_CIO | Characters-transferred weight factor. The unit used for this weight is billing units per character transferred. P_CIO is multiplied by the number of I/O characters transferred. | |
| P_LIO | Logical-I/O-request weight factor. The unit used for this weight is billing units per logical I/O request. P_LIO is multiplied by the number of logical I/O requests made. The number of logical I/O requests is total number of read and write system calls. |
The formula for calculating the whole process record SBU is as follows:
PSBU = (P_TIME * (P_STIME * stime + P_UTIME * utime + P_BWTIME * bwtime + P_RWTIME * rwtime)) + (P_MEM * (P_XMEM * coremem + P_VMEM * virtmem)) + (P_IO * (P_BIO * bio + P_CIO * cio + P_LIO * lio)); NSBU = (NP_TIME * (NP_STIME * stime + NP_UTIME * utime NP_BWTIME * bwtime + NP_RWTIME * rwtime)) + (NP_MEM * (NP_XMEM * coremem + NP_VMEM * virtmem)) + (NP_IO * (NP_BIO * bio + NP_CIO * cio + NP_LIO * lio)); SBU = P_BASIC * PSBU + NP_BASIC * NSBU; |
The variables in this formula are described as follows:
| Variable | Description | |
| stime | System CPU time in seconds | |
| utime | User CPU time in seconds | |
| bwtime | Block I/O wait time in seconds | |
| rwtime | Raw I/O wait time in seconds | |
| coremem | Core (physical) memory integral in Mbyte-minutes | |
| virtmem | Virtual memory integral in Mbyte-minutes | |
| bio | Number of blocks of data transferred | |
| cio | Number of characters of data transferred | |
| lio | Number of logical I/O requests |
The /etc/csa.conf file contains the configurable parameters that pertain to workload management SBUs.
The WKMG_NUM_QUEUES parameter sets the number of queues for which you want to set SBUs (the value must be set to at least 1). Each WKMG_QUEUE x variable in the configuration file has a queue name and an SBU pair associated with it (the total number of queue/SBU pairs must equal WKMG_NUM_QUEUES). The queue/SBU pairs define weights for the queues. If an SBU value is less than 1.0, there is an incentive to run jobs in the associated queue; if the value is 1.0, jobs are charged as though they are non-workload management jobs; and if the SBU is 0.0, there is no charge for jobs running in the associated queue. SBUs for queues not found in the configuration file are automatically set to 1.0.
The WKMG_NUM_MACHINES parameter sets the number of originating machines for which you want to set SBUs (the value must be at least 1). Each WKMG_MACHINE x variable in the configuration file has an originating machine and an SBU pair associated with it (the total number of machine/SBU pairs must equal WKMG_NUM_MACHINES). SBUs for originating machines not specified in /etc/csa.conf are automatically set to 1.0.
There is a set of weighting factors for each group of tape devices. By default, there are only two groups, tape and cart. The TAPE_SBU i parameters in /etc/csa.conf define the weighting factors for each group. There are SBUs associated with the follpwing:
Number of mounts
Device reservation time (seconds)
Number of bytes read
Number of bytes written
| Note: Tape support is not supported in this release. |
Accounting information is available from the workload management daemon. Data is written to the pacct file in the /var/csa/day directory.
In most cases, daemon accounting must be enabled by both the CSA subsystem and the daemon. “Setting Up CSA”, describes how to enable daemon accounting at system startup time. You can also enable daemon accounting after the system has booted.
You can enable accounting for a specified daemon by using the csaswitch command. For example, to start tape accounting, you should do the following:
/usr/sbin/csaswitch -c on -n tape |
Daemon accounting is disabled at system shutdown (see “Setting Up CSA”). It can also be disabled at any time by the csaswitch command when used with the off operand. For example, to disable workload management accounting, execute the following command:
/usr/sbin/csaswitch -c off -n wkmg |
These dynamic changes using csaswitch are not saved across a system reboot.
CSA accommodates the following user exits, which can be called from certain csarun states:
| csarun state | User exit | |
| ARCHIVE1 | /usr/sbin/csa.archive1 | |
| ARCHIVE2 | /usr/sbin/csa.archive2 | |
| FEF | /var/local/sbin/csa.fef | |
| USEREXIT | /usr/sbin/csa.user |
CSA accommodates the following user exit, which can be called from certain csaperiod states:
| csaperiod state | User exit | |
| USEREXIT | /usr/sbin/csa.puser |
These exits allow an administrator to tailor the csarun procedure (or csaperiod procedure) to the individual site's needs by creating scripts to perform additional site-specific processing during daily accounting. (Note that the following comments also apply to csaperiod).
While executing, csarun checks in the ARCHIVE1, ARCHIVE2, FEF and USEREXIT states for a shell script with the appropriate name.
If the script exists, it is executed via the shell . (dot) command. If the script does not exist, the user exit is ignored. The . (dot) command will not execute a compiled program, but the user exit script can. csarun variables are available, without being exported, to the user exit script. csarun checks the return status from the user exit and if it is nonzero, the execution of csarun is terminated.
Some examples of user exits are as follows:
rain1# cd /usr/lib/acct
rain1# cat csa.archive1
#!/bin/sh
mkdir -p /tmp/acct/pacct${DTIME}
cp ${WTIME_DIR}/${PACCT}* /tmp/acct/pacct${DTIME}
rain1# cat csa.archive2
#!/bin/sh
cp ${SPACCT} /tmp/acct
rain1# cat csa.fef
#!/bin/sh
mkdir -p /tmp/acct/jobs
/usr/lib/acct/csadrep -o /tmp/acct/jobs/dbin.${DTIME} -s ${SPACCT}
/usr/lib/acct/csadrep -n -V3 /tmp/acct/jobs/dbin.${DTIME}
|
By default, SBUs are calculated for all workload management jobs regardless of the workload management termination code of the job. If you do not want to bill portions of a workload management request, set the appropriate WKMG_TERM_xxxx variable (termination code) in the /etc/csa.conf file to 0, which sets the SBU for this portion to 0.0. This sets the SBU for this portion to 0.0. By default, all portions of a request are billed.
The following table describes the termination codes:
| Code | Description | |
| WKMG_TERM_EXIT | Generated when the request finishes running and is no longer in a queued state. | |
| WKMG_TERM_REQUEUE | Written for a request that is requeued. | |
| WKMG_TERM_HOLD | Written for a request that is checkpointed and held. | |
| WKMG_TERM_RERUN | Written when a request is rerun. | |
| WKMG_TERM_MIGRATE | Written when a request is migrated. |
| Note: The above descriptions of the termination codes are very generic. Different workload managers will tailor the meaning of these codes to suit their products. LSF currently only uses the WKMG_TERM_EXIT termination code. |
Modify the following variables in /etc/csa.conf if necessary:
| Variable | Description | |
| ACCT_FS | File system on which /var/csa resides. The default is /var. | |
| MAIL_LIST | List of users to whom mail is sent if fatal errors are detected in the accounting shell scripts. The default is root and adm for SGI ProPack 3 and csaacct for SGI ProPack 4. | |
| WMAIL_LIST | List of users to whom mail is sent if warning errors are detected by the accounting scripts at cleanup time. The default is root and adm for SGI ProPack 3 and csaacct for SGI ProPack 4. | |
| MIN_BLKS | Minimum number of free blocks needed in ${ACCT_FS} to run csarun or csaperiod. The default is 2000 free blocks. Block size is 1024 bytes. |
You can use the at command instead of cron to execute csarun periodically. If your system is down when csarun is scheduled to run via cron, csarun will not be executed until the next scheduled time. On the other hand, at jobs execute when the machine reboots if their scheduled execution time was during a down period.
You can execute csarun by using at in several ways. For example, a separate script can be written to execute csarun and then resubmit the job at a specified time. Also, an at invocation of csarun could be placed in a user exit script, /usr/sbin/csa.user , that is executed from the USEREXIT section of csarun. For more information, see “Setting up User Exits”.
By default, the /etc/csa.conf configuration file is used when any of the CSA commands are executed. You can specify a different file by setting the shell variable CSACONFIG to another configuration file, and then executing the CSA commands.
For example, you would execute the following commands to use the configuration file /tmp/myconfig while executing csarun:
CSACONFIG=/tmp/myconfig /usr/sbin/csarun 2> /var/csa/nite/fd2log |
You can use CSA to create accounting reports. The reports can be used to help track system usage, monitor performance, and charge users for their time on the system.
The CSA daily reports are located in the /var/csa/sum directory; periodic reports are located in the /var/csa/fiscal directory. To view the reports, go to the ASCII file rprt.MMDDhhmm in the report directories.
The CSA reports contain more detailed data than the other accounting reports. For CSA accounting, daily reports are generated by the csarun command. The daily report includes the following:
disk usage statistics
unfinished job information
command summary data
consolidated accounting report
last login information
daemon usage report
Periodic reports are generated by the csaperiod command. You can also create a disk usage report using the diskusg command.
This section describes the following reports:
This section describes the following reports:
The Consolidated Information Report is sorted by user ID and then project ID (project ID is not supported in this release). The following usage values are the total amount of resources used by all processes for the specified user and project during the reporting period.
| Heading | Description | |
| PROJECT NAME | Project associated with this resource usage information (not supported in this release) | |
| USER ID | User identifier | |
| LOGIN NAME | Login name for the user identifier | |
| CPU_TIME | Total accumulated CPU time in seconds | |
| KCORE * CPU-MIN | Total accumulated amount of Kbytes of core (physical) memory used per minute of CPU time | |
| KVIRT * CPU-MIN | Total accumulated amount of Kbytes of virtual memory used per minute of CPU time | |
| IOWAIT BLOCK | Total accumulated block I/O wait time in seconds | |
| IOWAIT RAW | Total accumulated raw I/O wait time in seconds |
The Unfinished Job Information Report describes jobs which have not terminated and are recycled into the next accounting period.
| Heading | Description | |
| JOB ID | Job identifier | |
| USERS | Login name of the owner of this job | |
| PROJECT ID | Project identifier associated with this job (not supported in this release) | |
| STARTED | Beginning time of this job |
The Disk Usage Report describes the amount of disk resource consumption by login name.
There are no column headings for this report. The first column gives the user identifier. The second column gives the login name associated with the user identifier. The third column gives the number of disk blocks used by this user.
The Command Summary Report summarizes command usage during this reporting period. The usage values are the total amount of resources used by all invocations of the specified command. Commands which were run only once are combined together in the "***other" entry. Only the first 44 command entries are displayed in the daily report. The periodic report displays all command entries.
| Heading | Description | |
| COMMAND NAME | Name of the command (program) | |
| NUMBER OF COMMANDS | Number of times this command was executed | |
| TOTAL KCORE-MINUTES | Total amount of Kbytes of core (physical) memory used per minute of CPU time | |
| TOTAL KVIRT-MINUTES | Total amount of Kbytes of virtual memory used per minute of CPU time | |
| TOTAL CPU | Total amount of CPU time used in minutes | |
| TOTAL REAL | Total amount of real (wall clock) time used in minutes | |
| MEAN SIZE KCORE | Average amount of core (physical) memory used in Kbytes | |
| MEAN SIZE KVIRT | Average amount of virtual memory used in Kbytes | |
| MEAN CPU | Average amount of CPU time used in minutes | |
| HOG FACTOR | Total CPU time used divided by the total real time (elapsed time) | |
| K-CHARS READ | Total number of characters read in Kbytes | |
| K-CHARS WRITTEN | Total number of characters written in Kbytes | |
| BLOCKS READ | Total number of blocks read | |
| BLOCKS WRITTEN | Total number of blocks written |
The Last Login Report shows the last login date for each login account listed.
There are no column headings for this report. The first column is the last login date. The second column is the login account name.
Daemon Usage Report shows reports usage of the workload management and tape daemons (tape is not supported in this release). This report has several individual reports depending upon if there was workload management or tape daemon activity within this reporting period.
The Job Type Report gives the workload management and interactive job usage count.
| Heading | Description | |
| Job Type | Type of job (interactive or workload management) | |
| Total Job Count | Number and percentage of jobs per job type | |
| Tape Jobs | Number and percentage of tape jobs associated with these interactive and workload management job (not supported in this release) |
The CPU Usage Report gives the workload management and interactive job usage related to CPU usage.
| Heading | Description | |
| Job Type | Type of job (interactive or workload management) | |
| Total CPU Time | Total amount of CPU time used in seconds and percentage of CPU time | |
| System CPU Time | Amount of system CPU time used of the total and the percentage of the total time which was system CPU time usage | |
| User CPU Time | Amount of user CPU time used of the total and the percentage of the total time which was user CPU time usage |
The workload management Queue Report gives the following information for each workload management queue.
| Queue Name | Name of the workload management queue | |
| Number of Jobs | Number of jobs initiated from this queue | |
| CPU Time | Amount of system and user CPU times used by jobs from this queue and percentage of CPU time used | |
| Used Tapes | How many jobs from this queue used tapes | |
| Ave Queue Wait | Average queue wait time before initiation in seconds |
This section describes two periodic reports as follows:
The following usage values for the Consolidated accounting report are the total amount of resources used by all processes for the specified user and project during the reporting period.
| Heading | Description | |
| PROJECT NAME | Project associated with this resource usage information | |
| USER ID | User identifier | |
| LOGIN NAME | Login name for the user identifier | |
| CPU_TIME | Total accumulated CPU time in seconds | |
| KCORE * CPU-MIN | Total accumulated amount of Kbytes of core (physical) memory used per minute of CPU time of processes | |
| KVIRT * CPU-MIN | Total accumulated amount of Kbytes of virtual memory used per minute of CPU time | |
| IOWAIT BLOCK | Total accumulated block I/O wait time in seconds | |
| IOWAIT RAW | Total accumulated raw I/O wait time in seconds | |
| DISK BLOCKS | Total number of disk blocks used | |
| DISK SAMPLES | Number of times disk accounting was run to obtain the disk blocks used value | |
| FEE | Total fees charged to this user from csachargefee(8) | |
| SBUs | System billing units charged to this user and project |
The following information summarizes command usage during the defined reporting period. The usage values are the total amount of resources used by all invocations of the specified command. Unlike the daily command summary report, the periodic command summary report displays all command entries. Commands executed only once are not combined together into an "***other" entry but are listed individually in the periodic command summary report.
| Heading | Description | |
| COMMAND NAME | Name of the command (program) | |
| NUMBER OF COMMANDS | Number of times this command was executed | |
| TOTAL KCORE-MINUTES | Total amount of Kbytes of core (physical) memory used per minute of CPU time | |
| TOTAL KVIRT-MINUTES | Total amount of Kbytes of virtual memory used per minute of CPU time | |
| TOTAL CPU | Total amount of CPU time used in minutes | |
| TOTAL REAL | Total amount of real (wall clock) time used in minutes | |
| MEAN SIZE KCORE | Average amount of core (physical) memory used in Kbytes | |
| MEAN SIZE KVIRT | Average amount of virtual memory used in Kbytes | |
| MEAN CPU | Average amount of CPU time used in minutes | |
| HOG FACTOR | Total CPU time used divided by the total real time (elapsed time) | |
| K-CHARS READ | Total number of characters read in Kbytes | |
| K-CHARS WRITTEN | Total number of characters written in Kbytes | |
| BLOCKS READ | Total number of blocks read | |
| BLOCKS WRITTEN | Total number of blocks written |
The man command provides online help on all resource management commands. To view a man page online, type man commandname .
This section covers these the following topics:
The following user-level man pages are provided with CSA software:
| User-level man page | Description | |
| ||
| csacom(1) | Searches and prints the CSA process accounting files. | |
| ja(1) | Starts and stops user job accounting information. |
The following administrator man page is provided with CSA software:
| Administrator man page | Description |
| |
| csaaddc(8) | Combines cacct records. |
| csabuild(8) | Organizes accounting records into job records. |
| csachargefee(8) | Charges a fee to a user. |
| csackpacct(8) | Checks the size of the CSA process accounting file. |
| csacms(8) | Summarizes command usage from per-process accounting records |
| csacon(8) | Condenses records from the sorted pacct file. |
| csacrep(8) | Reports on consolidated accounting data. |
| csadrep(8) | Reports daemon usage. |
| csaedit(8) | Displays and edits the accounting information. |
| csagetconfig(8) | Searches the accounting configuration file for the specified argument. |
| csajrep(8) | Prints a job report from the sorted pacct file. |
| csarecy(8) | Recycles unfinished jobs into the next accounting run. |
| csaswitch(8) | Checks the status of, enables or disables the different types of CSA, and switches accounting files for maintainability. |
| csaverify(8) | Verifies that the accounting records are valid. |
The Linux CSA application interface library allows software applications to manipulate and obtain status about Linux CSA accounting methods.
| Application interface man page | Description | |
| ||
| csa_auth(3) | Checks to determine if caller has the necessary capabilities. | |
| csa_check(3) | Checks a kernel, daemon, or record accounting state. | |
| csa_halt(3) | Stops all accounting methods. | |
| csa_jastart(3) | Startd job accounting. | |
| csa_jastop(3) | Stops job accounting. | |
| csa_kdstat(3) | Gets the kernel and daemon accounting status. | |
| csa_rcdstat(3) | Gets the record accounting status. | |
| csa_start(3) | Gets the user ID of a job. | |
| csa_stop(3) | Stops specified accounting method(s). | |
| csa_wracct(3) | Writes the accounting record to file. |